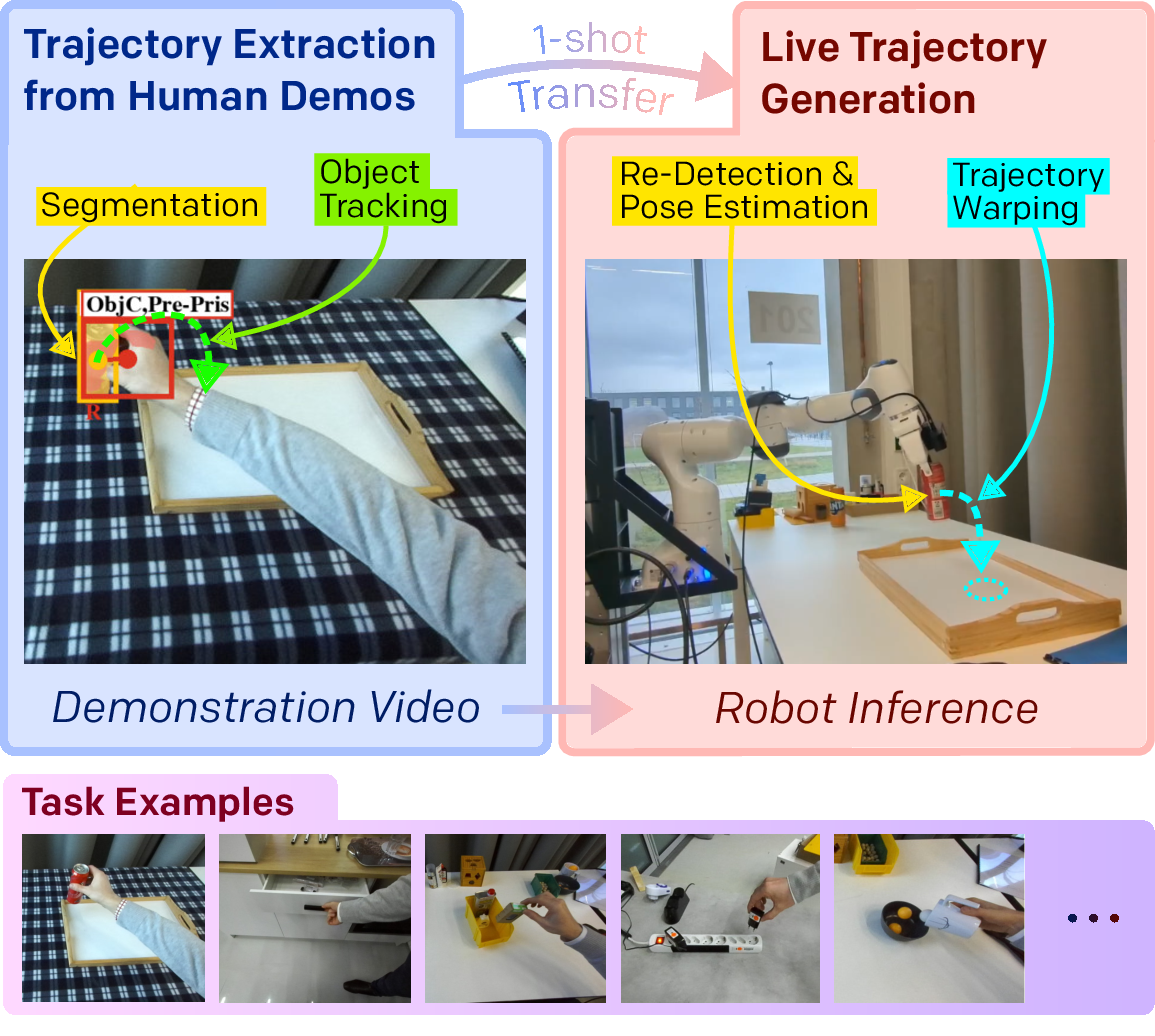
Teaching robots new skills quickly and conveniently is crucial for the broader adoption of robotic systems. In this work, we address the problem of one-shot imitation from a single human demonstration, given by an RGB-D video recording. We propose a two-stage process. In the first stage we extract the demonstration trajectory offline. This entails segmenting manipulated objects and determining their relative motion in relation to secondary objects such as containers. In the online trajectory generation stage, we first re-detect all objects, then warp the demonstration trajectory to the current scene and execute it on the robot. To complete these steps, our method leverages several ancillary models, including those for segmentation, relative object pose estimation, and grasp prediction. We systematically evaluate different combinations of correspondence and re-detection methods to validate our design decision across a diverse range of tasks. Specifically, we collect and quantitatively test on demonstrations of ten different tasks including pick-and-place tasks as well as articulated object manipulation. Finally, we perform extensive evaluations on a real robot system to demonstrate the effectiveness and utility of our approach in real-world scenarios.